How to Train a ML Model to Defeat APT Cyber Attacks
Round 1: Introducing Fuchikoma
Round 2: Fuchikoma VS CyAPTEmu: The Weigh In
Round 3: Fuchikoma v0: Learning the Sweet Science
Round 4: Fuchikoma v1: Finding the Fancy Footwork
Round 5: Fuchikoma v2: Jab, Cross, Hook, Perfecting the 1-2-3 Punch Combo
Round 6: Fuchikoma v3: Dodge, Counterpunch, Uppercut!
Fuchikoma v0: the baby years
The thought experiment Fuchikoma v0 model gave insight into the four main challenges when designing a threat hunting ML model: having a weak signal, imbalanced data sets, a lack of high-quality data labels, and the lack of an attack storyline.
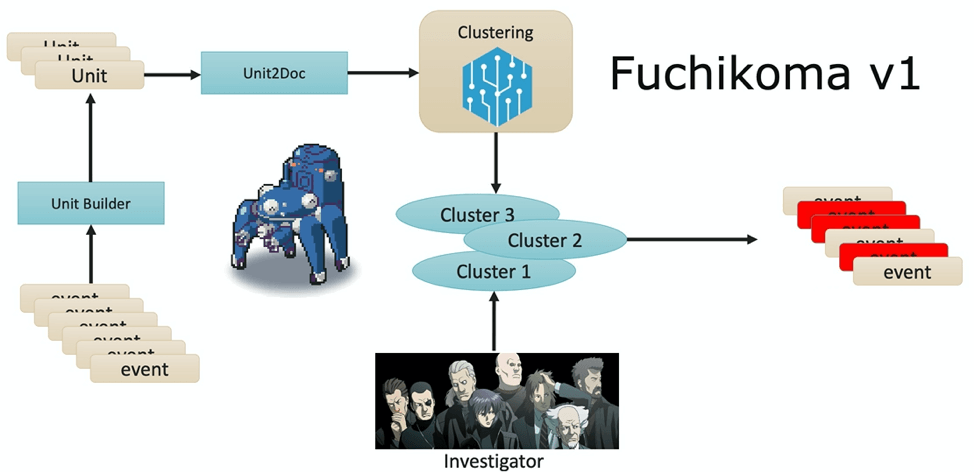
Fuchikoma v1: entering childhood
Fuchikoma v1 resolved the first challenge: having a weak signal. An analysis unit (AU) builder was introduced into the ML pipeline; each process creation event was altered into an AU–a mini process tree that links the original process creation event to its parent and three tiers of child processes. TF-IDF was used for vectorization of the command lines of the processes into the Unit2Doc. Now that each event had useful and contextual information as an AU, ML algorithms could group similar AUs into clusters, leaving our investigators with significantly less labeling to be done. Unfortunately, k-means (the chosen ML algorithm) wasn’t enough on its own. While clustering may yet prove to be useful, highlighting outliers was chosen as it could address some of the drawbacks of clustering. It was decided that Fuchikoma v2 would need more components to its pipeline.
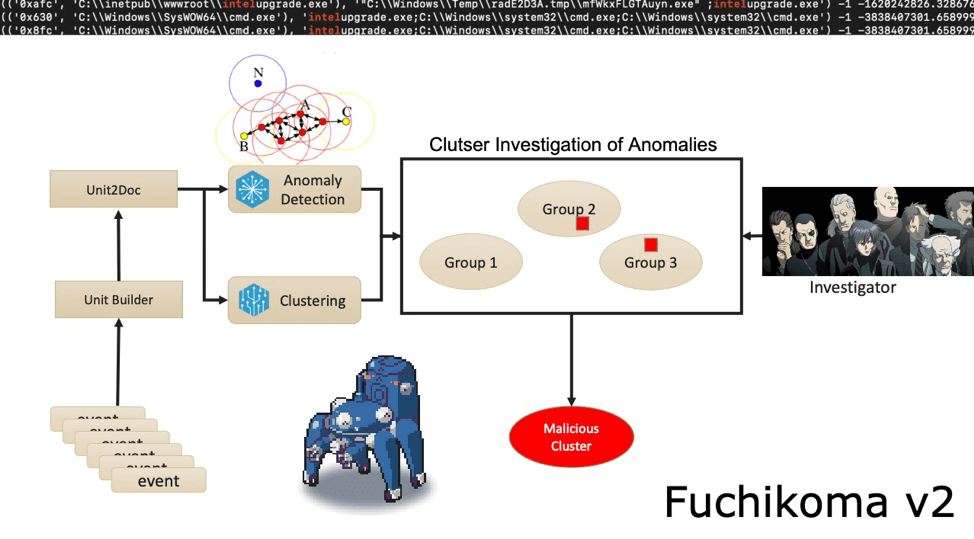
Fuchikoma v2: fighting its way through hormones and high school
As discussed in Part 3, only 1.1 percent of the process creation events in our dataset were malicious. Since the number of attack activities is an incredibly low percentage of one day’s total events, C.K. Chen and team reasoned malicious activities would be abnormal compared to other activities.
Therefore, an anomaly detection component was applied to find the most abnormal AUs. Different algorithms specializing in anomaly detection were implemented: Local Outlier Factor (LOF), IsolationForest (IF), and DBScan.
LOF (Local Outlier Factor) is essentially a score that tells how likely a particular data point is an outlier/anomaly (or in Fuchikoma’s terms, malicious). More specifically, LOF measures the local deviation of the density of a given sample with respect to its neighbors. Samples that have a substantially lower density than their neighbors are considered outliers.
IF (IsolationForest) isolates each point in a data set and splits them into outliers or inliers (anomalous or normal). This split depends on how long it takes to separate the points. Outliers should be easier to separate since fewer conditions are needed to separate them from inliers. IF could be useful for huge data sets of multiple dimensions, such as Fuchikoma’s.
DBScan (Density-Based Spatial Clustering and Applications with Noise) groups together points that are close to each other based on a distance measurement and a minimum number of points. DBScan is especially useful for data that contains clusters of similar density, such as Fuchikoma’s benign clusters. DBScan also highlights outliers in low-density regions, which helps Fuchikoma locate those pesky malicious events even accurately.
Some false alerts might still occur and need manual analysis; however, benign clusters, the larger group in our dataset (98.9 percent), should no longer need to be investigated. This would significantly reduce the investigating team’s workload and have the added benefit of resolving the second challenge, imbalanced data sets, as the investigators would now only be labeling a small set of abnormal data.
The results were encouraging.
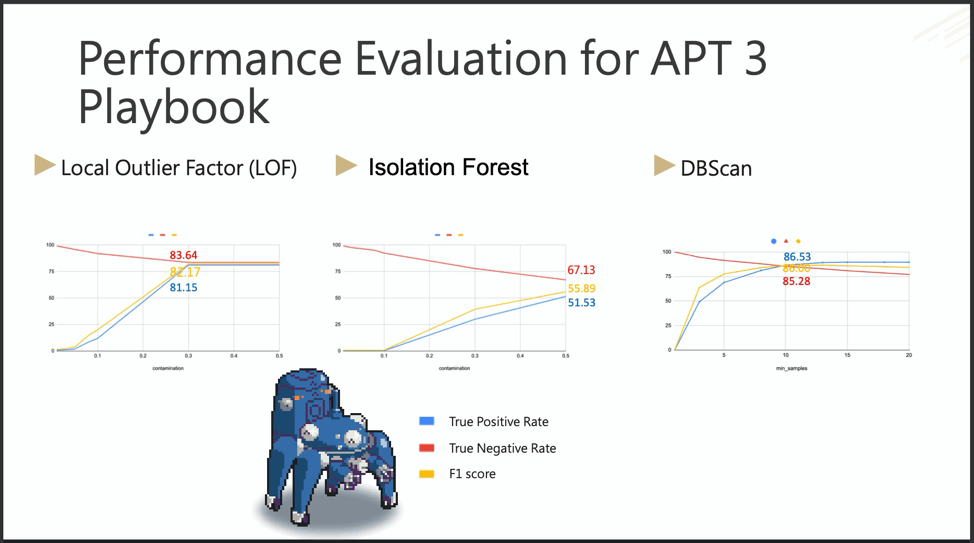
IF was the terrible first date. LOF met your friends. DBScan met your parents–the keeper.
As mentioned in Part 2 of this series, the goal of CyCraft APT Emulator (CyAPTEmu) is to generate attacks on Windows machines in a virtualized environment. CyAPTEmu will send two waves of attacks; each utilizing a different pre-constructed playbook. Empire was used to run the first playbook, modeled after APT3. Metasploit was used to run the second playbook, which C.K. and team called Dogeza.
DBScan outperformed LOF and IF in the APT3 Playbook, but how would DBScan prove against C.K. and team’s custom Dogeza playbook?
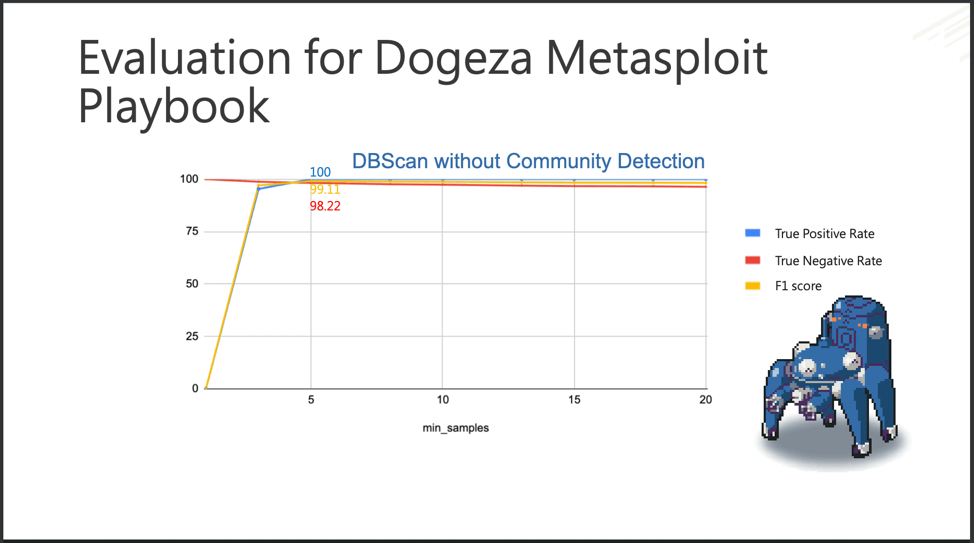
DBScan outperformed LOF and IF in both the APT3 and Dogeza playbook
If you’re confused by Fuchikoma’s charts above, don’t be; you just probably aren’t too familiar with a confusion matrix (also known as an error matrix), which is the backbone of statistical classification in ML. A true positive (TP) is when our friend Fuchikoma correctly identifies a malicious event. A true negative (TN) is when Fuchikoma correctly identifies a benign event.
In ML, there are performance metrics that help evaluate and improve ML models, such as recall, precision, and accuracy. All of these are technical terms and are used in different cases, similar to pentesting, vulnerability accessing, or red team evaluations; all important but are required for different tasks.
One performance metric you will see a lot is the F1-score, also known as the F-score or F-measure. The F1-score is used when the cost of false positives or false negatives is high. Not being able to identify malicious activities (false negatives) could be disastrous for an organization and, at worst, could cost hundreds of millions in breach recovery and fines. At the same time, we don’t want to overwhelm our team of security analysts with false positives, as spending time on false positives could also be disastrous when facing an attack.
The F1-score is used to evaluate ML models whose goals are to keep false positives and false negatives to a minimum if not zero. F1-scores range from 1 (a model with perfect precision and recall) to 0 (a model that makes you question what you’ve been doing with your life). In terms of Fuchikoma, C.K. Chen and team represented the F1-score as a percentage. Fuchikoma v2 scored 99.11 percent on its F1-score.
Now that we’ve had a simplistic introduction to the basics of ML, let’s check back in with our team of elite investigators at Section 9 and hear their evaluation of Fuchikoma v2.

Section 9, Ghost in the Shell: S.A.C. 2nd GiG (2002, Production i.G.)
Single events in isolation do not contain enough information to determine if they are a threat or not. Data needs to be contextual in order for it to be useful. Analysis units, which contain contextual child and parent process information, were added into the ML pipeline and are then clustered and labeled later in the pipeline.

Analysis Unit consisting of TF-IDF vectorized command lines
In our boxing ring metaphor, this means Fuchikoma can relate everything it sees to everything else. The wooden stool in CyAPTEmu’s corner isn’t related to camera flashing in the background. The backward swing of our opponent’s arm is definitely related to the punch that is now quickly speeding towards us. Ouch, was that a glove contacting my face? While Fuchikoma is able to relate events to each other through contextual data within each AU, our friend Fuchikoma still has trouble determining causality.
Challenge Two: Imbalanced Data Sets [RESOLVED]
As stated before, a typical workday in an organization’s environment could see billions of diverse events. Only a tiny portion of which (1.1 percent in the training data) would actually be related to a real attack. This massive imbalance in data sets (normal versus malicious) created two big problems: (1) inefficient labeling time and (2) a less than ideal amount of malicious samples. However, due to prioritizing anomaly detection, benign clusters (98.9 percent of the training data) no longer needed to be labeled–dramatically reducing the size of data needed to be labeled and the time needed to label said data.